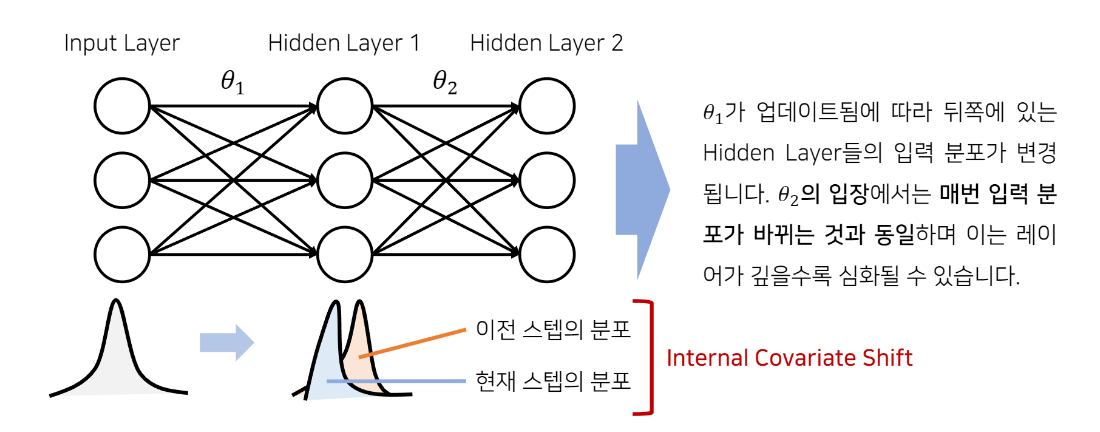
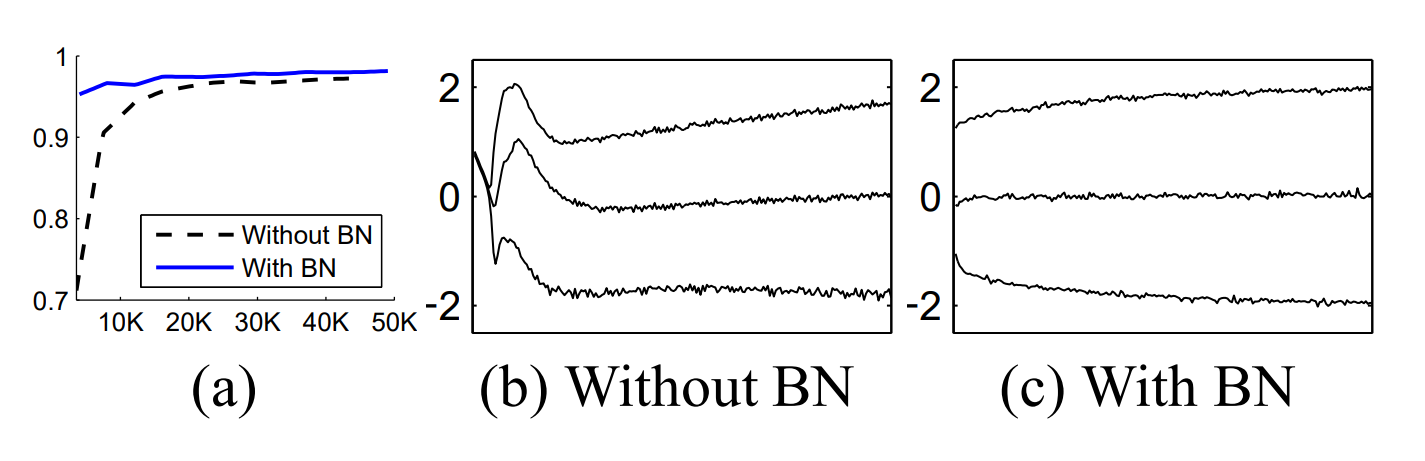
직관적으로 internal covariate shift를 막기 위해 분포가 고정되게 하려면 위와 같이 각 히든레이어의 output에 normalization을 취할 수 있습니다. 이는 논문의 알고리즘에서 설명하는 방법입니다.
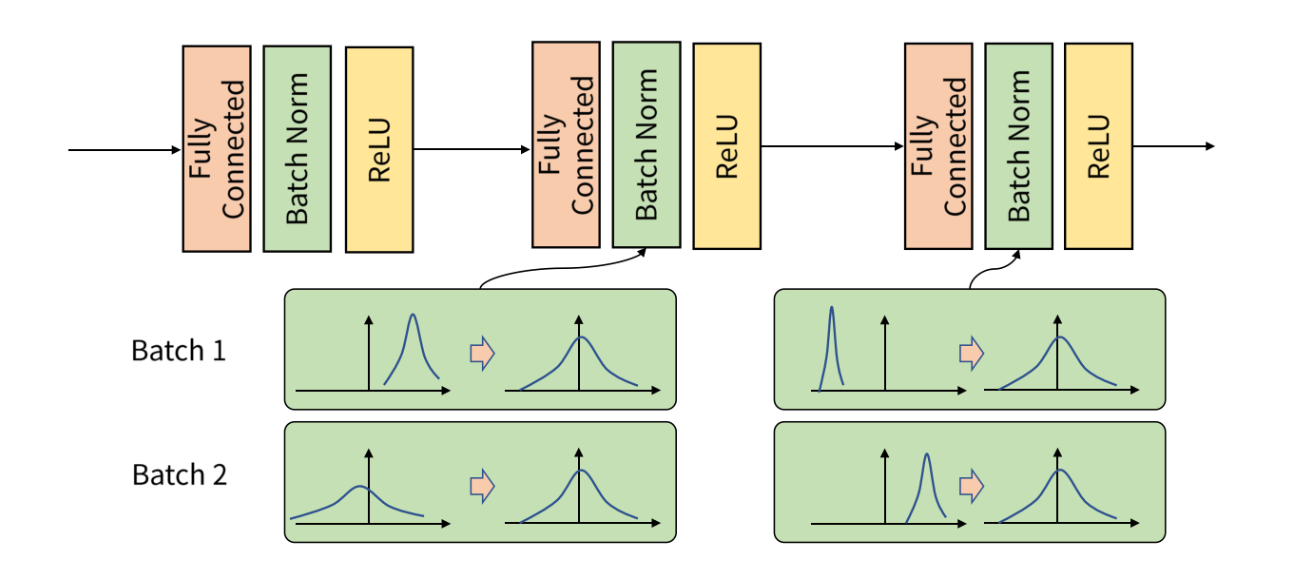
그러나 찾아본 흔히 Fully connected-layer와 activation function사이에 batchnormalization layer를 놓습니다. 이는 논문의 실험에서 사용한 방법입니다.
정리하자면 normalization을 적용하는 위치는 문제마다 다르지만 흔히들 위와 같이 Fully connected layer와 activation function사이에 놓는게 일반적이며 이는 비교적 자유로운 편이라 할 수 있습니다.
위와 같은 방법으로 normalization만 취하게 된다면 네트워크의 표현력을 감소시킬 수 있습니다. 시그모이드의 linear regime에 값들이 대다수 위치하기 때문입니다.(뉴럴넷은 선형+비선형 변환을 통해서 높은 표현력을 지닙니다.단순히 normalization만 취하면 비선형함수의 역할이 감소하게 됩니다.)
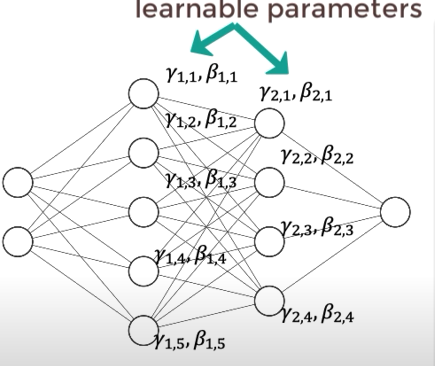
figure3 - DNN with learnable parameter
따라서 normalization된 값을 적절하게 shifting,scailing하도록 각 뉴런에 붙는 learnable parameter\(\gamma,\beta\)를 추가합니다.
정리하자면 BatchNormalization은 Batch단위로 normalization을 통해 internal covariate shift를 막고 동시에 learnable parameter로 shifting,scailing함으로서 nonlinearity를 유지하여 gradient vanishing(exploding),학습의 어려움,표현력의 감소와 같은 문제를 해결했다고 할 수 있습니다.
Implementation
Training
Figure4 - BN Algorithm
notation
논문의 알고리즘 부분에서는 Batchnormalization은 activation function바로 다음에 위치하는 것을 기준으로 설명합니다.
\(\mathcal{B} = \{x_{1...m}\}\)는 크기가 m인 batch를 입력했을때 임의의 노드에서 출력된 m개의 scalar값이다.(activation function을 통과한 후이다.)m개의 output입니다.
\(\mu_{\mathcal{B}}\),\(\sigma^2_{\mathcal{B}}\)는 각각 \(\mathcal{B}\)의 평균,분산을 의미합니다.
\(\hat{x_i}\)는 \(\mathcal{B}\)에 속하는 임의의 원소 \(x_i\)에 normalization한 값입니다.
여기서 \(\epsilon\)은 매우작은 값을 의미하며 분산이 0일때의 연산이 불안정해지는 것을 막습니다.
\(y_i\)는 learnable parameter인 \(\gamma,\beta\)에 대한 값이며 \(\text{BN}_{\gamma,\beta}(x_i)\)를 계산한 결과입니다.
explanation - 먼저 크키가m인 batch에 대해서 어떤 노드에서 m개의 스칼라값인 \(\mathcal{B}\)가 출력됩니다. - \(\mathcal{B}\)의 평균,분산을 계산합니다. - \(\forall x_i \in \mathcal{B}\)에 대하여 normalization을 취하고 learnable parameter인 \(\gamma,\beta\)를 곱합니다.
학습된 \(\gamma\),\(\beta\)의 예시 Normalization연산이 필요없다고 학습한 경우,nonlinearity를 유지하는 것이 좋은 경우,identity를 유지하는게 좋은 경우 \[\gamma \approx \sqrt{var[x]},\beta \approx \mathbb{E}[x] \rightarrow \hat{x_i}\approx x_i \]Normalization연산이 필요하다고 학습한 경우,linearity를 가지는 것이 경우,identity를 버리는게 좋은 경우 \[\gamma \approx 1,\beta \approx 0 \rightarrow \hat{x_i} \approx \frac{x_i-\mu_\mathcal{B}}{\sqrt{\sigma_\mathcal{B}^2-\epsilon}}\]
Test or Inference
training에서는 minibatch단위로 평균,분산을 구하여 normalization할 수 있지만 test에서는 이와는 다르게 minibatch단위로 data가 입력되지 않을뿐더러 또한 입력되는 데이터가 한개여도 올바르게 예측해야 원합니다.
따라서 이때에는 training에서 각각의 배치들로부터 얻은 평균들과 분산들을 저장해놓고 test에서는 이 값들로 다시 평균을 취하여(평균들의 평균) normalization을 취합니다.
이때 단순한 평균을 취하는 것이 아니라 어느정도 학습된 네트워크에서 얻어진 minibatch들의 데이터를 더 많이 고려하기 위해서 movingaverage나 exponentialaverage를 사용합니다.
movingaverage는 학습단계에서 얻어진 값(평균,분산)의 일부를 직접 지정하여 평균을 구하고 exponentialaverage는 어느정도 안정된 상태의 값(나중값)들에 가중치를 부여하여 평균,분산을 구하는 방법입니다.